1. Strings and Arrays
1.1 Diagram to show Java String’s Immutability
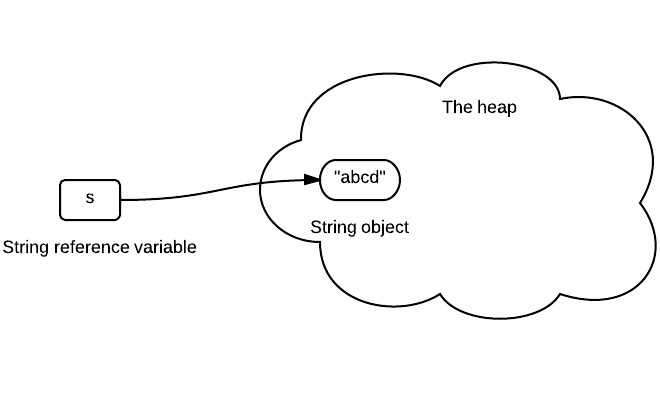
1.1.1 Declare a string
String s = "abcd";
s stores the reference of the string object. The arrow below should be interpreted as "store reference of".
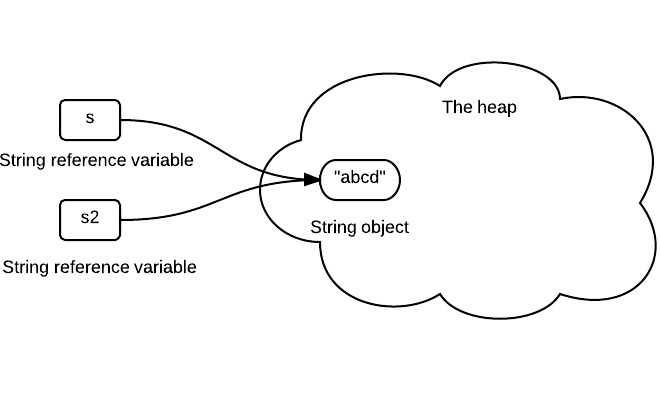
1.1.2 Assign one string variable to another string
String s2 = s;
s2 stores the same reference value, since it is the same string object.
1.1.3 Concat string
s = s.concat("ef");
s now stores the reference of newly created string object.

1.1.4 Summary
Once a string is created in memory(heap), it can not be changed. We should note that all methods of String do not change the string itself, but rather return a new String.
If we need a string that can be modified, we will need StringBuffer or StringBuilder. Otherwise, there would be a lot of time wasted for Garbage Collection, since each time a new String is created. Here is an example of StringBuilder usage.
1.2 The substring() Method in JDK 6 and JDK 7
The substring(int beginIndex, int endIndex) method in JDK 6 and JDK 7 are different. Knowing the difference can help you better use them. For simplicity reasons, in the following substring() represent the substring(int beginIndex, int endIndex) method.
1.2.1 what substring() does?
The substring(int beginIndex, int endIndex) method returns a string that starts with beginIndex and ends with endIndex-1.
String x = "abcdef";
x = x.substring(1,3);
System.out.println(x);
1.2.2 What happens when substring() is called?
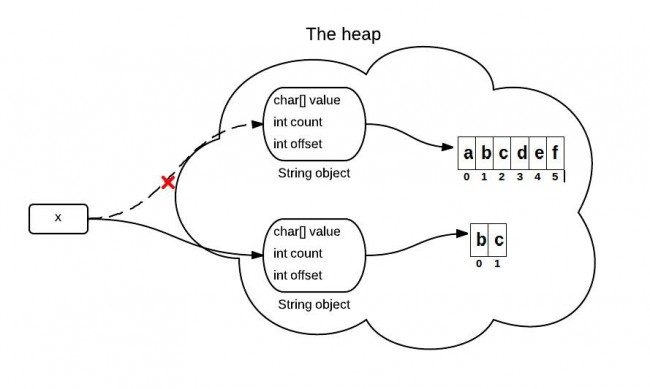
You may know that because x is immutable, when x is assigned with the result of x.substring(1,3), it points to a totally new string like the following:
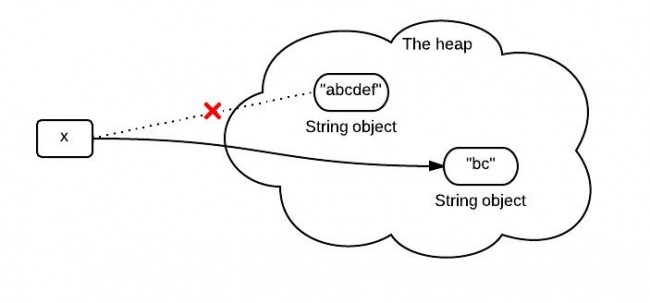
However, this diagram is not exactly right or it represents what really happens in the heap. What really happens when substring() is called is different between JDK 6 and JDK 7.
1.2.3. substring() in JDK 6
String is supported by a char array. In JDK 6, the String class contains 3 fields: char value[], int offset, int count. They are used to store real character array, the first index of the array, the number of characters in the String.
When the substring() method is called, it creates a new string, but the string's value still points to the same array in the heap. The difference between the two Strings is their count and offset values.
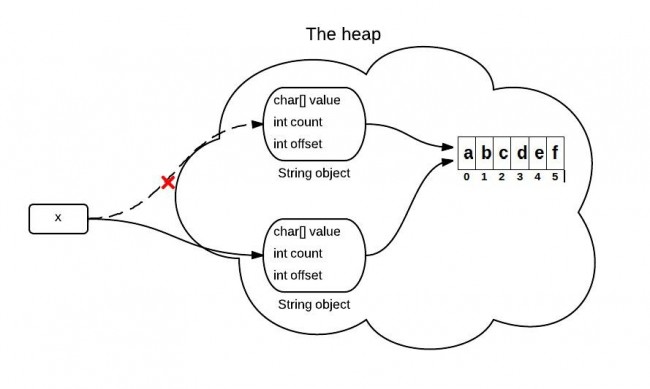
The following code is simplified and only contains the key point for explain this problem.
//jdk 6
String(int offset,int count,char value[]){
this.value = value;
this.offset = offset;
this.count = count;
}
public String substring(int beginIndex, int endIndex) {
//check boundary
return new String(offset + beginIndex, endIndex - beginIndex, value);
}
1.2.4
A problem caused by substring() in JDK 6
If you have a VERY long string, but you only need a small part each time by using substring(). This will cause a performance problem, since you need only a small part, you keep the whole thing. For JDK 6, the solution is using the following, which will make it point to a real sub string:
x = x.substring(x, y) + ""
//JDK 7
public String(char value[], int offset, int count) {
//check boundary
this.value = Arrays.copyOfRange(value, offset, offset + count);
}
public String substring(int beginIndex, int endIndex) {
//check boundary
int subLen = endIndex - beginIndex;
return new String(value, beginIndex, subLen);
}
1.3 Why String is immutable in Java ?
String is an immutable class in Java. An immutable class is simply a class whose instances cannot be modified. All information in an instance is initialized when the instance is created and the information can not be modified. There are many advantages of immutable classes. This article summarizes why String is designed to be immutable. A good answer depends on deep understanding of memory, synchronization, data structures, etc.
1.3.1 Requirement of String Pool
String pool (String intern pool) is a special storage area in Method Area. When a string is created and if the string already exists in the pool, the reference of the existing string will be returned, instead of creating a new object and returning its reference.
The following code will create only one string object in the heap.
String string1 = "abcd";
String string2 = "abcd";
Here is how it looks:
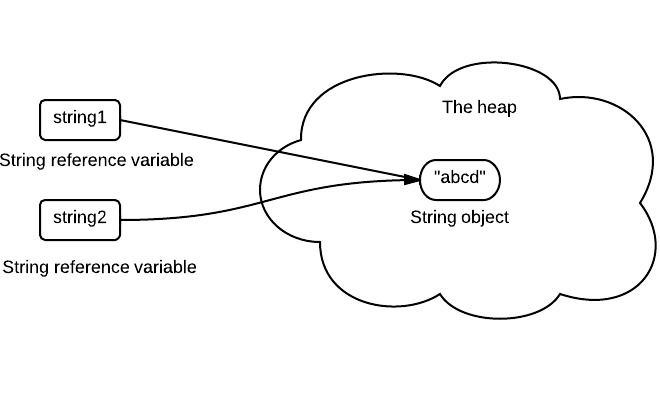
If string is not immutable, changing the string with one reference will lead to the wrong value for the other references.
1.3.2 Caching Hashcode
The hashcode of string is frequently used in Java. For example, in a HashMap. Being immutable guarantees that hashcode will always the same, so that it can be cashed without worrying the changes.That means, there is no need to calculate hashcode every time it is used. This is more efficient.
In String class, it has the following code:
private int hash;//this is used to cache hash code.
1.3.3 Facilitating the Use of Other Objects
To make this concrete, consider the following program:
HashSet<String> set = new HashSet<String>();
set.add(new String("a"));
set.add(new String("b"));
set.add(new String("c"));
for(String a: set)
a.value = "a";
In this example, if String is mutable, it's value can be changed which would violate the design of set (set contains unduplicated elements). This example is designed for simplicity sake, in the real String class there is no value field.
1.3.4. Security
String is widely used as parameter for many java classes, e.g. network connection, opening files, etc. Were String not immutable, a connection or file would be changed and lead to serious security threat. The method thought it was connecting to one machine, but was not. Mutable strings could cause security problem in Reflection too, as the parameters are strings.
Here is a code example:
boolean connect(string s){
if (!isSecure(s)) {
throw new SecurityException();
}
//here will cause problem, if s is changed before this by using other references.
causeProblem(s);
}
1.3.5 Immutable objects are naturally thread-safe
Because immutable objects can not be changed, they can be shared among multiple threads freely. This eliminate the requirements of doing synchronization.
In summary, String is designed to be immutable for the sake of efficiency and security. This is also the reason why immutable classes are preferred in general.
1.4 Create Java String Using ” ” or Constructor?
In Java, a string can be created by using two methods:
String x = "abc";
String y = new String("abc");
What is the difference between using double quotes and using constructor?
1.4.1 Double Quotes vs. Constructor
This question can be answered by using two simple code examples.
Example 1:
String a = "abcd";
String b = "abcd";
System.out.println(a == b); // True
System.out.println(a.equals(b)); // True
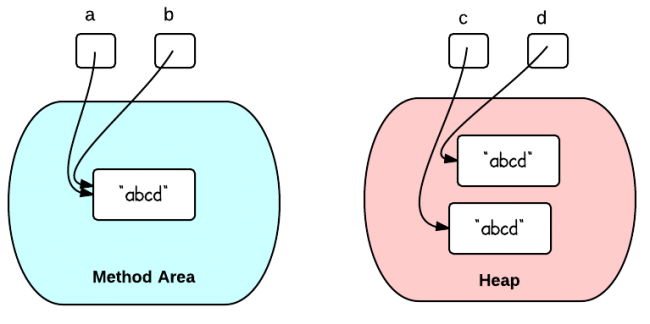
a==bis true because a and b are referring to the same string literal in the method area. The memory references are the same.
When the same string literal is created more than once, only one copy of each distinct string value is stored. This is called "string interning". All compile-time constant strings in Java are automatically interned.
Example 2:
String c = new String("abcd");
String d = new String("abcd");
System.out.println(c == d); // False
System.out.println(c.equals(d)); // True
c==d is false because c and d refer to two different objects in the heap. Different objects always have different memory references.
This diagram illustrate the two situations above:
1.4.2 Run-Time String Interning
Thanks to LukasEder (his comment below):
String interning can still be done at run-time, even if two strings are constructed with constructors:
String c = new String("abcd").intern();
String d = new String("abcd").intern();
System.out.println(c == d); // Now true
System.out.println(c.equals(d)); // True
1.4.3 When to Use Which
Because the literal "abcd" is already of type String, using constructor will create an extra unnecessary object.
Therefore, double quotes should be used if you just need to create a String.
If you do need to create a new object in the heap, constructor should be used.
1.5 String is passed by “reference” in Java
this is a classic question of Java. Many similar questions have been asked on stackoverflow, and there are a lot of incorrect/incomplete answers. The question is simple if you don't think too much. But it could be very confusing, if you give more thought to it.
1.5.1 A code fragment that is interesting & confusing
public static void main(String[] args) {
String x = new String("ab");
change(x);
System.out.println(x);
}
public static void change(String x) {
x = "cd";
}
It prints "ab".
In C++, the code is as follows:
void change(string &x) {
x = "cd";
}
int main(){
string x = "ab";
change(x);
cout << x << endl;
}
it prints "cd".
1.5.2 Common confusing questions
x stores the reference which points to the "ab" string in the heap. So when x is passed as a parameter to the change() method, it still points to the "ab" in the heap like the following:
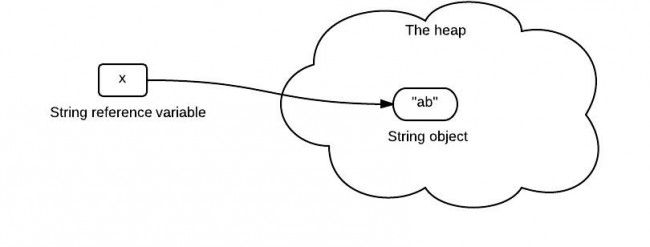
It seems to be a pretty reasonable explanation. They are clear that Java is always pass-by-value. But what is wrong here?
1.5.3 What the code really does?
The explanation above has several mistakes. To understand this easily, it is a good idea to briefly walk though the whole process.
When the string "ab" is created, Java allocates the amount of memory required to store the string object. Then, the object is assigned to variable x, the variable is actually assigned a reference to the object. This reference is the address of the memory location where the object is stored.
The variable x contains a reference to the string object. x is not a reference itself! It is a variable that stores a reference(memory address).
Java is pass-by-value ONLY. When x is passed to the change() method, a copy of value of x (a reference) is passed. The method change() creates another object "cd" and it has a different reference. It is the variable x that changes its reference(to "cd"), not the reference itself.
The following diagram shows what it really does.
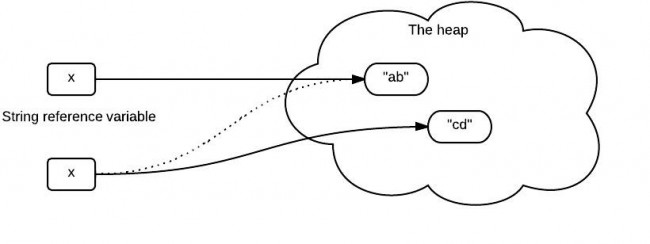
1.5.4 The wrong explanation
The problem raised from the first code fragment is nothing related with string immutability. Even if String is replaced with StringBuilder, the result is still the same. The key point is that variable stores the reference, but is not the reference itself!
1.5.5 Solution to this problem
If we really need to change the value of the object. First of all, the object should be changeable, e.g., StringBuilder. Secondly, we need to make sure that there is no new object created and assigned to the parameter variable, because Java is passing-by-value only.
public static void main(String[] args) {
StringBuilder x = new StringBuilder("ab");
change(x);
System.out.println(x);
}
public static void change(StringBuilder x) {
x.delete(0, 2).append("cd");
}
1.6 Start from length & length() in Java
First of all, can you quickly answer the following question?
Without code autocompletion of any IDE, how to get the length of an array? And how to get the length of a String?
I asked this question to developers of different levels: entry and intermediate. They can not answer the question correctly or confidently. While IDE provides convenient code autocompletion, it also brings the problem of "surface understanding". In this post, I will explain some key concepts about Java arrays.
The answer:
int[] arr = new int[3];
System.out.println(arr.length);//length for array
String str = "abc";
System.out.println(str.length());//length() for string
The question is why array has the length field but string does not? Or why string has the length() method while array does not?
1.6.1 Why arrays have length property?
First of all, an array is a container object that holds a fixed number of values of a single type. After an array is created, its length never changes[1]. The array's length is available as a final instance variable length. Therefore, length can be considered as a defining attribute of an array.
An array can be created by two methods: 1) an array creation expression and 2) an array initializer. When it is created, the size is specified.
An array creation expression is used in the example above. It specifies the element type, the number of levels of nested arrays, and the length of the array for at least one of the levels of nesting.
This declaration is also legal, since it specifies one of the levels of nesting.
int[][] arr = new int[3][];
An array initializer creates an array and provides initial values for all its components. It is written as a comma-separated list of expressions, enclosed by braces { and }.
For example,
int[] arr = {1,2,3};
1.6.2 Why there is not a class "Array" defined similarly like "String"?
Since an array is an object, the following code is legal.
Object obj = new int[10];
An array contains all the members inherited from class Object(except clone). Why there is not a class definition of an array? We can not find an Array.java file. A rough explanation is that they're hidden from us. You can think about the question - if there IS a class Array, what would it look like? It would still need an array to hold the array data, right? Therefore, it is not a good idea to define such a class.
Actually we can get the class of an array by using the following code:
int[] arr = new int[3];
System.out.println(arr.getClass());
Output:
class [I
"class [I" stands for the run-time type signature for the class object "array with component type int".
1.6.3 Why String has length() method?
The backup data structure of a String is a char array. There is no need to define a field that is not necessary for every application. Unlike C, an Array of characters is not a String in Java.
1.7 How to Check if an Array Contains a Value in Java Efficiently?
How to check if an array (unsorted) contains a certain value? This is a very useful and frequently used operation in Java. It is also a top voted question on Stack Overflow. As shown in top voted answers, this can be done in several different ways, but the time complexity could be very different. In the following I will show the time cost of each method.
1.7.1 1. Four Different Ways to Check If an Array Contains a Value
1) Using List:
public static boolean useList(String[] arr,String targetValue){
return Arrays.asList(arr).contains(targetValue);
}
2) Using Set:
public static boolean useSet(String[] arr, String targetValue) {
Set<String> set = new HashSet<String>(Arrays.asList(arr));
return set.contains(targetValue);
}
3) Using a simple loop:
public static boolean useLoop(String[] arr, String targetValue) {
for(String s: arr){
if(s.equals(targetValue))
return true;
}
return false;
}
4) Using Arrays.binarySearch():
- The code below is wrong, it is listed here for completeness. binarySearch() can ONLY be used on sorted arrays. You will see the result is weird when running the code below.
public static boolean useArraysBinarySearch(String[] arr, String targetValue) {
int a = Arrays.binarySearch(arr, targetValue);
if(a > 0)
return true;
else
return false;
}
1.7.2 Time Complexity
The approximate time cost can be measured by using the following code. The basic idea is to search an array of size 5, 1k, 10k. The approach may not be precise, but the idea is clear and simple.
public static void main(String[] args) {
String[] arr = new String[] { "CD", "BC", "EF", "DE", "AB"};
//use list
long startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
useList(arr, "A");
}
long endTime = System.nanoTime();
long duration = endTime - startTime;
System.out.println("useList: " + duration / 1000000);
//use set
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
useSet(arr, "A");
}
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("useSet: " + duration / 1000000);
//use loop
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
useLoop(arr, "A");
}
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("useLoop: " + duration / 1000000);
//use Arrays.binarySearch()
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
useArraysBinarySearch(arr, "A");
}
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("useArrayBinary: " + duration / 1000000);
}
Result:
useList: 13
useSet: 72
useLoop: 5
useArraysBinarySearch: 9
Use a larger array (1k):
String[] arr = new String[1000];
Random s = new Random();
for(int i=0; i< 1000; i++){
arr[i] = String.valueOf(s.nextInt());
}
Result:
useList: 112
useSet: 2055
useLoop: 99
useArrayBinary: 12
Use a larger array (10k):
String[] arr = new String[10000];
Random s = new Random();
for(int i=0; i< 10000; i++){
arr[i] = String.valueOf(s.nextInt());
}
Result:
useList: 1590
useSet: 23819
useLoop: 1526
useArrayBinary: 12
Clearly, using a simple loop method is more efficient than using any collection. A lot of developers use the first method, but it is inefficient. Pushing the array to another collection requires spin through all elements to read them in before doing anything with the collection type.
The array must be sorted, if Arrays.binarySearch() method is used. In this case, the array is not sorted, therefore, it should not be used.
Actually, if you really need to check if a value is contained in some array/collection efficiently, a sorted list or tree can do it in O(log(n)) or hashset can do it in O(1).
1.8 Java Varargs Examples
1.8.1 What is Varargs in Java?
Varargs (variable arguments) is a feature introduced in Java 1.5. It allows a method take an arbitrary number of values as arguments.
public static void main(String[] args) {
print("a");
print("a", "b");
print("a", "b", "c");
}
public static void print(String ... s){
for(String a: s)
System.out.println(a);
}
1.8.2 How Varargs Work?
When varargs facility is used, it actually first creates an array whose size is the number of arguments passed at the call site, then puts the argument values into the array, and finally passes the array to the method.
1.8.3 When to Use Varargs?
As its definition indicates, varargs is useful when a method needs to deal with an arbitrary number of objects. One good example from Java SDK is String.format(String format, Object... args). The string can format any number of parameters, so varargs is used.
String.format("An integer: %d", i); String.format("An integer: %d and a string: %s", i, s);
1.9 What exactly is null in Java?
Let's start from the following statement:
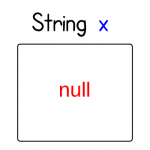
String x = null;
1.9.1 What exactly does this statement do?
Recall what is a variable and what is a value. A common metaphor is that a variable is similar to a box. Just as you can use a box to store something, you can use a variable to store a value. When declaring a variable, we need to set its type.
There are two major categories of types in Java: primitive and reference. Variables declared of a primitive type store values; variables declared of a reference type store references. In this case, the initialization statement declares a variables “x”. “x” stores String reference. It is null here.
The following visualization gives a better sense about this concept.
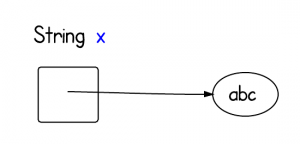
If x = "abc", it looks like the following:
1.9.2 What exactly is null in memory?
What exactly is null in memory? Or What is the null value in Java?
First of all, null is not a valid object instance, so there is no memory allocated for it. It is simply a value that indicates that the object reference is not currently referring to an object.
From JVM Specifications:
The Java Virtual Machine specification does not mandate a concrete value encoding null.
I would assume it is all zeros of something similar like itis on other C like languages.
1.9.3 What exactly is x in memory?
Now we know what null is. And we know a variable is a storage location and an associated symbolic name (an identifier) which contains some value. Where exactly x is in memory?
From the diagram of JVM run-time data areas, we know that since each method has a private stack frame within the thread's steak, the local variable are located on that frame.